
EN
发票、合同、银行回单,格式千变万化。处理这些非标长尾文档,正成为财务与运营部门极大的痛点。
OCR识别准确率低,,频频错漏。系统认不出,最终只能靠人眼看。这导致了居高不下的二次人工核对成本,效率不增反降。
那么,全部接入通用大模型就能解决吗?答案是否定的。盲目堆砌大模型,企业将面临两个新问题。一是高昂的算力成本。二是高频处理场景下的排队与响应延迟。
在此背景下,一种更为务实的方案脱颖而出,“大小模型协同”的智能文档处理方案,兼顾准确率与算力成本。
在升级智能文档处理能力时,企业通常会有以下瓶颈。
1. 二次人工成本居高不下
一线业务每天产生大量非标单据。传统的模板识别技术缺乏泛化能力。面对异构表单,关键信息抽取极易失败。业务人员不得不投入大量时间进行手工核对与补录。
2. 高并发与长尾解析的矛盾
高频并发遇上长尾疑难,系统极易崩溃。遇到月末结算高峰,传统架构无法动态调配计算资源。此时,系统不是排队堵塞,就是响应超时。
3. 数据断点引发合规风险
早期系统往往是模块化拼凑。扫描归档一套系统,OCR识别一套接口,各环节相互割裂。数据链条存在严重断点。在后评估或合规审计时,审核结论难以有效追溯到原始影像。这极大地增加了企业的合规风险。

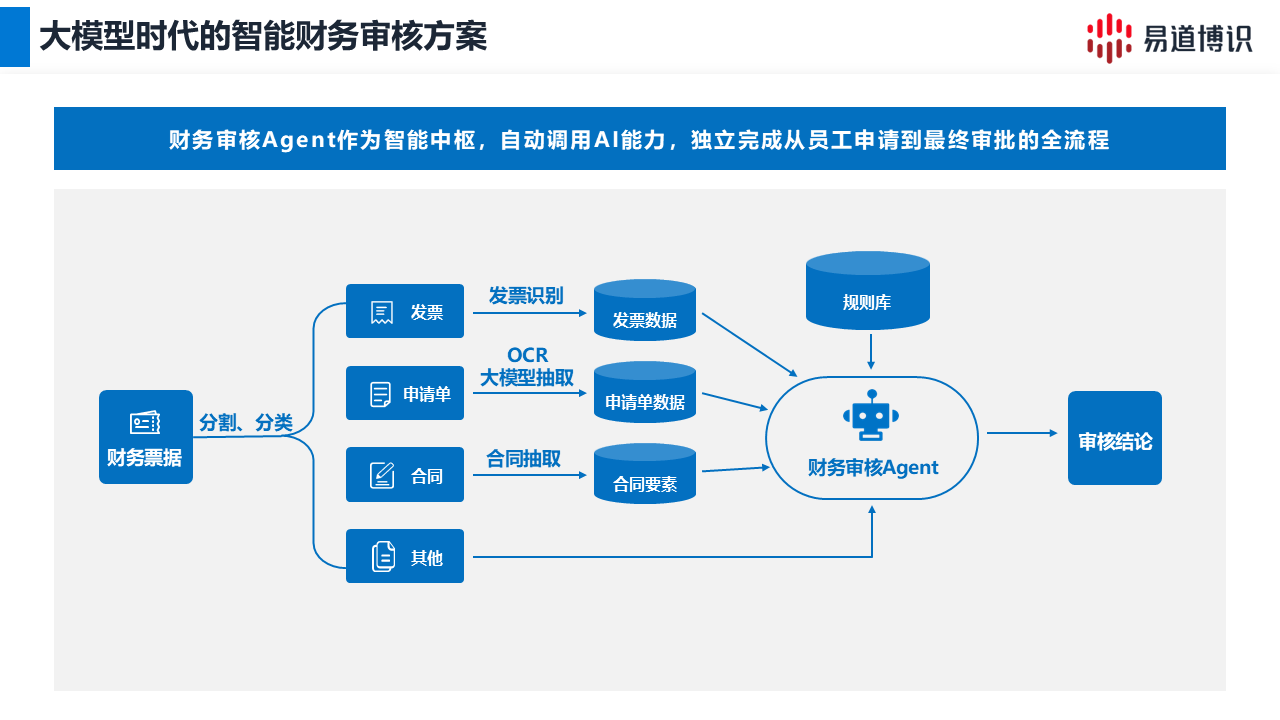
面对上述痛点,单一模型已无法胜任。行业内的领先方案,正在走向精细化的协同架构。以易道博识推出大小模型协同,给出了新的文档处理思路.
易道博识创新落地了“智能路由抽取”机制。文档输入后,系统会自动判断并分流。
●小模型处理高频文档:针对标准化证件及定式票据,由传统OCR模型负责。它主打批量抽取,保证秒级响应。月末并发高峰,也能轻松应对。
●大模型攻坚长尾文档:针对复杂的非标单据,系统自动路由至大模型。利用大模型的泛化理解能力,进行深度精准抽取。
在这套协同机制的支撑下,不论文档格式多复杂,关键信息的提取准确率均跃升至99.5%以上。
引入大小模型协同的智能文档系统,不仅提升了OCR的可用性,更实现了端到端业务闭环的效率飞跃。
1. 零代码配置,规则“分钟级上线”
过去,只要监管出台细则,或者内部风控策略发生变动,企业就得向IT排期。例如修改交通报销额度限制,需要重新编写校验代码,业务响应极慢。
在易道博识DocFlux中,前端业务人员凭借自然语言,即可进行可视化配置。输入“高铁不得高于二等座限额”,逻辑验证节点即刻生成。规则一经设定,即刻生效。真正实现了业务规则的零代码、分钟级上线。
2. 全程可追溯,确保合规透明
所有的数据抽取明细和审核风控信号,全都在可视化看板中直观呈现。得益于引擎保留的信息位置锚点,哪怕是一处细微的审核异常,也能直接回溯,并精准高亮在原位影像上。
每一项机器核验依据,都清清楚楚。这完全满足了严监管行业对审计可解释性的严苛要求。
1. 引入大小模型双引擎,成本高吗?
不会。这正是该架构的核心财务优势。日常海量高频任务由算力占用极小的小模型负责识别。只有非标长尾文档,才会路由至大模型。因此,整体算力消耗远低于纯大模型方案。
2. 这套架构,能否融入现有业务系统?
完全可以。易道博识的这套方案采用组件式设计,提供标准化的业务接口。无论您是想替换掉工作流中某个“卡脖子”的节点,还是计划重构一整套从业务采集到核心ERP归档的一体化平台,它都能以灵活的微服务形式快速集成。





