
EN
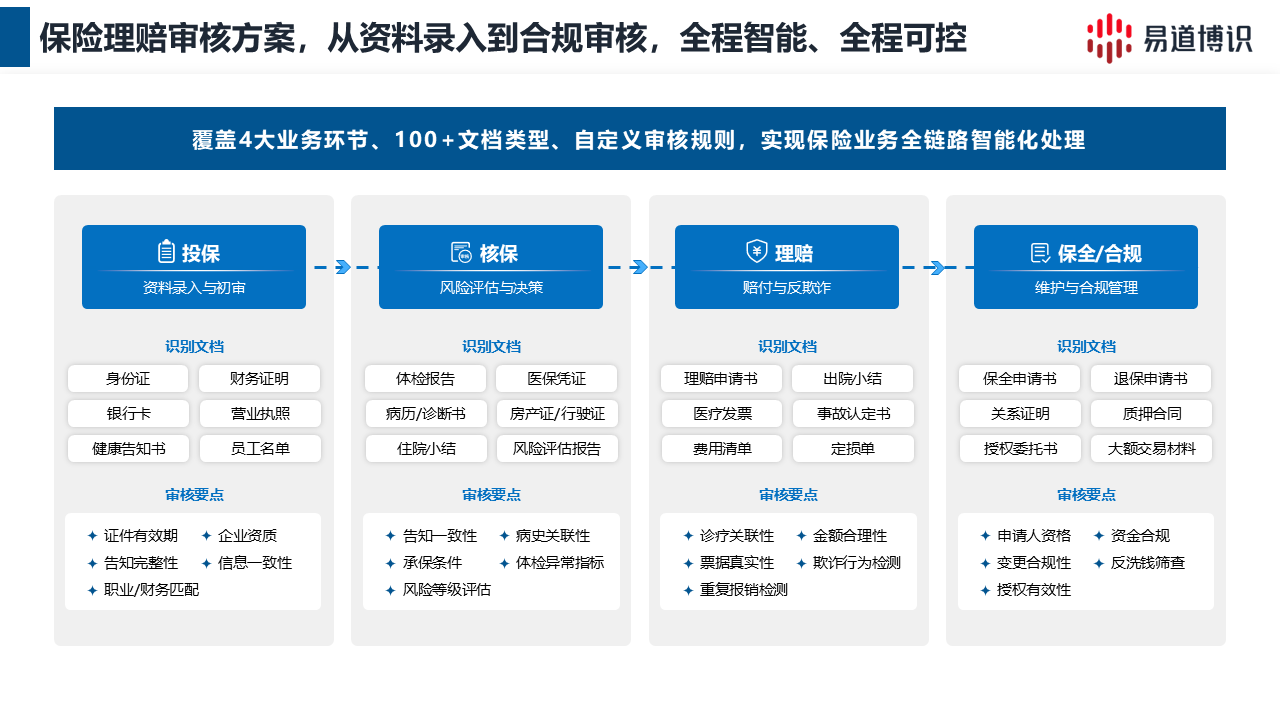
保险的理赔审核,长期受制于两大人工痛点:繁琐的前端分类录入,以及复杂的后端规则审核。
先看前端的分类录入。案件高峰期,理赔人员面对的是海量且杂乱的医疗档案。门诊发票、出院小结、明细清单往往混杂在一起。纯靠人工肉眼去逐页拆分、归类,再把核心数据逐个敲进系统。这不但耗费极高的基础工时,也极易产生录入错误。
再看后端的业务审核。进入核赔环节后,面对复杂的免赔额计算与自费药扣减政策,传统模式依然依赖人工去逐条比对明细。一旦审核人员疲劳或判定标准不一,就极易引发错赔、漏赔以及相应的合规隐患。
针对这一业务断点,易道博识推出了智能文档工作流(DocFlux)。该平台将“异构单票自动拆套抽取”与“零代码审核规则引擎”深度融合。系统打通了从单据采集分类、结构化录入,到最终业务逻辑校验的端到端流程。
理赔单据天然具有高度的复杂性。不同层级医院的发票版式各异,病历带有大量专业术语,甚至掺杂手写体。传统的模板匹配技术在此类场景下完全失效。针对这一难点,系统底层重构了解析逻辑。
1、大小模型智能分流引擎
系统不再采用单一的提取方式,而是根据文档复杂度进行自动路由分流。对于身份证、增值税发票等高频标准票据,系统调用“小模型”实现秒级的高并发处理。对于出院小结、诊断证明等非标的长尾文档,系统则直接调用“大模型”进行深度的语义解析。这种机制有效平衡了算力成本与识别精度,确保核心字段的综合准确率超过 99.5%。

2、多维数据交叉校验机制
系统的核心价值并非仅停留在“把字读出来”。它同时具备底层逻辑推理的能力。系统能自动完成基础要素的完整性校验。更重要的是,它能在系统层面实现跨单据的信息一致性比对。例如:系统会自动核算长达数十页的清单明细总额,并与门诊发票上的对冲金额进行自动校验。这种多维核验极大减轻了人工对账的压力。
从“辅助人工录单”走向“全流程自动化直赔”,是对系统端到端能力的真实考量。以下是智能文档工作流在实际业务流转中的核心表现:
1、兼容 200 余类复杂票种与高并发处理
前端接入能力决定了系统的吞吐量上限。该产品全面支持寿险、健康险及财险业务线所涉及的 200 余种票据类型。系统涵盖了病历、处方笺、乃至财险定损的维修清单。面对打包上传的理赔卷宗,平台单文件最大支持 200M 并发解析。系统自动完成材料的拆套分拣与信息抽取,过程无需人工预干预介入。
2、业务主导的零代码规则维护
保险机构的理算规则变动频繁。以往调整系统赔付规则需要重写代码,周期长且极易阻塞业务。该系统极大地释放了 IT 资源。业务理赔人员可直接使用自然语言配置规则。只需输入“住院天数超过30天需强制转人工复核”或“特定自费药予以拦截”,系统即可在分钟级上线生效,实现了真正的业务主导。
3、100% 影像溯源追查
合规审计是保险经营的底线。任何一笔机器拒赔或扣减都必须有源头依据支撑。系统构建了可视化的数据溯源体系。在业务看板上,对于所有触发了拦截规则的异常字段,系统都能在原始单据影像上予以高亮标记。所有判定依据一目了然,全面满足了内外部严格的合规审计要求。
1、医生手写病历非常潦草,系统如何保障识别准确率?
准确率不受字迹干扰。系统底层搭载了手写体增强识别算法。理算遇到印章重叠、折痕或模糊字迹时,大模型会基于医疗上下文进行语义推理。自动校正语法及术语偏差,输出高置信度的数据。
2、医疗明细清单长达几十页,能OCR识别抽取吗?
坚决阻断错行漏列。系统针对非标表格专门应用了版面分析技术。结合视觉语言智能模型,系统能精准还原表单原始的行列层级。即使理赔原件在扫描复印时存在严重歪斜或底色干扰。系统照样实现精准抓取,确保费用明细笔笔对齐。
3、系统对接难吗?上线是否需要庞大的 IT 实施团队?
实施周期极短。平台采用标准的产品化组件封装,可提供轻量化 API 接口。企业可自主选择私有化或云端部署。最关键的是,后续维护完全去 IT 化。理赔业务人员可随时用自然语言(对话般的功能)新增或排查审核规则。彻底丢掉沉重的系统开发包袱。





