
EN
专业的报表OCR识别录入系统通过高精度识别、智能模板和自动逻辑校验,将非结构化报表转化为结构化数据,极大提升金融机构的数据处理效率与准确性。
对于银行、证券、保险等金融机构而言,财报是评估企业信用、洞察投资价值的核心依据。然而,处理海量、格式各异的纸质或PDF财报,长期依赖耗时耗力的人工录入与复核,已成为业务敏捷性与风险控制的关键瓶颈。本文将深度解析一款专业级财报OCR系统如何从技术内核到业务价值,全面升级金融机构的数据能力。
一个常见的误区是认为任何OCR工具都能识别财报。事实上,两者在目标和技术路径上存在本质差异。
●目标维度: 通用OCR的目标是“读文”,即尽可能准确地还原文本内容;而财报OCR的目标是“识数”并“理解结构”,它需要理解“资产负债表”是一个整体,并知道“流动资产”与“流动负债”之间存在勾稽关系。
●技术维度: 通用OCR模型训练数据来源广泛,对财报中紧凑的数字、缺失的表格线、特定的会计科目名称识别效果不佳。专业系统则使用海量财务文档进行专项训练,对数字和表格的识别精度有数量级的提升。
●输出维度: 通用OCR输出的是无序的文本行或格子,仍需大量人工整理;专业财报OCR输出的是按会计科目分类、可直接导入数据库或分析软件的结构化数据记录。
该系统为解决财报处理难题,构建了一个层层递进的技术闭环,经测试,在5分钟内即可录入原先需要2小时人工录入的财报。
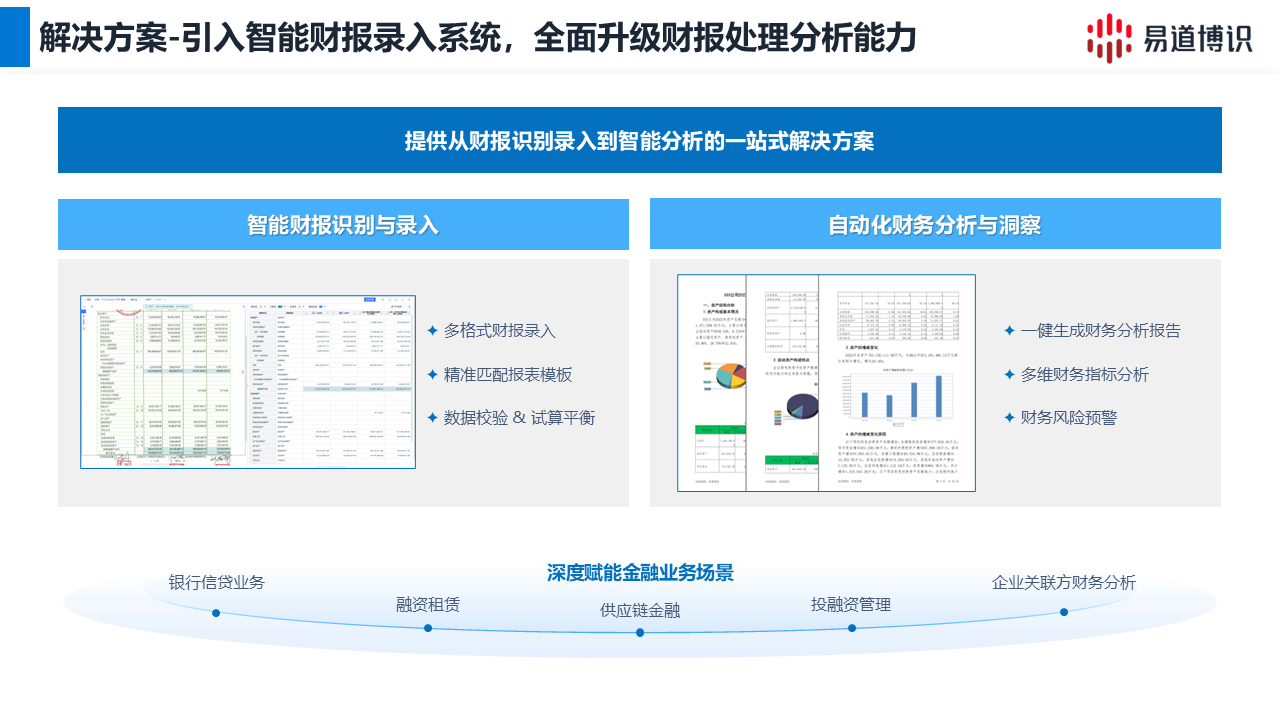
1.基础层:高精度OCR识别引擎。 系统不仅采用先进的OCR核心,更关键的是针对金融文档进行了全方位优化。其图像预处理模块能自动校正因扫描造成的倾斜、扭曲,并通过去噪、锐化提升图像质量。随后的版面分析模块能精准定位表格区域,确保每一个数据单元格都被正确捕捕获。
2.认知层:智能模板适配与科目识别。 系统超越了一般字符识别,具备了初步的“阅读理解”能力。它预置了覆盖主流会计准则的模板库,并能智能关联“营业收入”、“主营收入”等不同表述的同一科目。更重要的是其自学习能力,面对新报表格式,可通过少量样本进行训练,快速生成新模板,极大提升了系统的适应性和可持续性。
3.风控层:内置财务逻辑校验机制。 经验表明,超过20%的企业提交财报存在不同程度的勾稽关系错误。系统内嵌了丰富的校验规则,可自动进行跨单元格、跨页面的数据逻辑检查,如检查“资产=负债+所有者权益”是否平衡,并对不匹配、异常波动的数据点进行醒目标记与风险提示,为审计与风控人员提供了第一道高效防线。
4.价值层:自动化数据结构化与输出。 系统的终极目标是将非结构化信息转化为可计算的数据资产。它能够将识别并校验后的数据,按预设格式输出为Excel、JSON等标准接口,并可与金融机构内部的信贷审批系统、风险管理平台、商业智能系统进行无缝集成,打通了从文档到决策的“最后一公里”,实现了端到端的自动化。

问题:财报OCR识别录入系统与现有业务系统集成难度大吗?
回答:系统提供标准API接口和多种数据输出格式(如Excel, JSON),与常见的信贷、风控系统集成经验成熟,技术难度可控,实施周期明确。
问题:财报OCR识别录入如何保证长期的识别准确率?
回答:系统具备持续学习能力。通过用户对识别结果的反馈和修正,模型可以进行迭代优化,从而在面对新字体、新格式时能自我进化,保持高准确率。





