
EN
对于金融、审计等行业的专业人士来说,处理财报表格是一项基础但耗时的工作。而财报OCR系统的核心价值,就是解决那些最棘手的表格识别问题。
对于金融与审计行业的从业者而言,财报数据提取是一项高频且对精度要求极严的作业。专用财报OCR系统的核心价值,在于解决通用方案无法处理的表格结构化难题,从而实现从非结构化文档到结构化数据的高效转换。
通用光学字符识别(OCR)技术的底层逻辑是“文本序列化”,即单纯地将图像像素映射为可编辑的线性文本。
这种技术路径在处理财报时存在本质缺陷。虽然通用引擎能准确识别出“1,000”这一数值字符,但它缺乏语义理解能力,无法判定该数值是隶属于“流动资产”下的“货币资金”,还是归属于“负债”科目下的“短期借款”。面对财报中普遍存在的多栏布局、跨页表格、多层嵌套表头以及缺乏边框线的“无线表格”,仅凭字符识别会导致数据逻辑断裂,输出结果往往是杂乱无序的文本堆砌。
表格复原的难点不在于字符本身的识别精度,而在于对表格“逻辑拓扑结构”的重建。
先进的财报识别系统摒弃了单一的文本识别模式,转而采用多阶段的智能处理流。该流程通过深度学习模型,系统性地解决从版面定位到逻辑重组的技术挑战。
系统首先对文档进行全局视觉扫描。算法将自动区分文档中的不同版面元素,精确框选表格区域,同时剥离正文叙述、页眉页脚及页码等非表格干扰项。这一步骤确保了后续计算资源能够集中于核心数据区域,为高精度的结构化处理确立边界。
系统利用计算机视觉技术检测显性与隐性的表格分割线,定位所有文本块的物理坐标,并解析其行列属性。在此过程中,模型会构建一个包含行索引与列索引的逻辑骨架,确立“父级表头”与“子项数据”之间的多维映射关系。例如,系统将在此阶段锁定“资产”作为顶级维度,并建立其与下辖“货币资金”等子科目的层级关联。
在稳固的结构框架建立之后,系统启动OCR引擎进行字符提取。
基于已解析的行列坐标,OCR引擎针对性地识别每个单元格内的具体数值与文本。这种“先结构,后内容”的处理次序至关重要:若缺乏准确的逻辑框架,即便是100%的字符识别率也无法生成可被机器理解的数据。只有当结构解析无误时,识别出的数字才能转化为具有业务价值的财务信息。
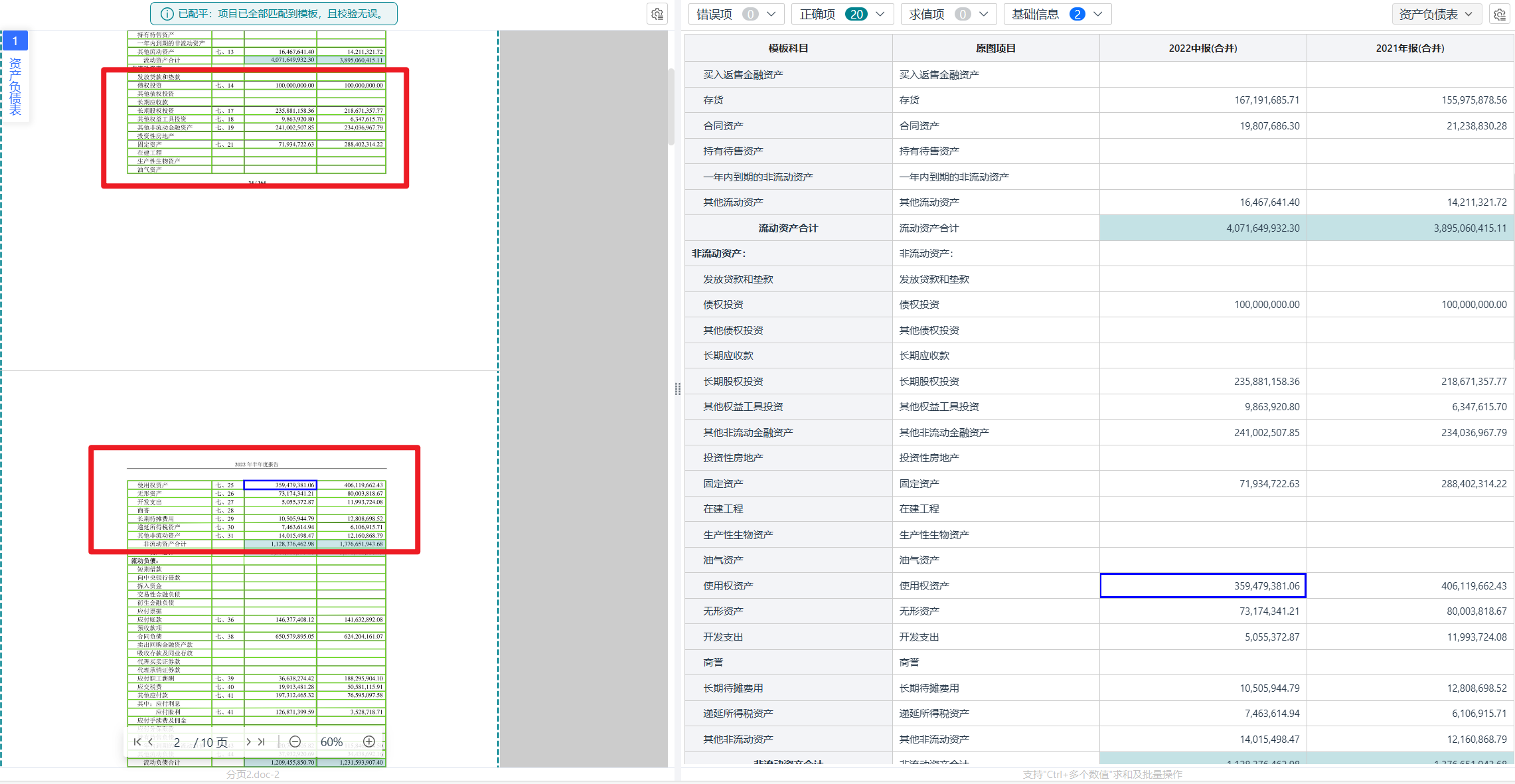
“跨页断裂”是处理财报表格时最让人头疼的问题之一。一个完整的财务报表,可能从第10页开始,到第11页才结束。
●传统OCR的失败点: 许多系统在处理跨页表格时会“失忆”。它们在第11页时,已经忘记了第10页的表头是什么,导致第11页的数据全部丢失或错配。
●易道博识智能财报OCR的解决方案是,在第一步“版面分析”时,就会检测到“跨页”的信号。它会通过表格拼接,主动寻找第10页的“断裂处”和第11页的“接续处”,先将它们拼接成一个完整的表格。拼接完成后,系统会应用表头语义继承”逻辑,将第10页的表头(如“项目”、“本期金额”、“上期金额”)自动应用到第11页的数据行上。这样,无论表格有多长、断裂了多少次,系统都能确保每一行数据都与正确的表头机关联。
问题:财报OCR的识别准确率能达到多少?
回答: 这是一个双重指标。对于数字和文字的OCR识别率,目前主流技术(如易道博识)可以达到99.9%以上。财报一次配平率超95%。
问题:财报OCR识别录入系统与现有业务系统集成难度大吗?
回答:系统提供标准API接口和多种数据输出格式(如Excel, JSON),与常见的信贷、风控系统集成经验成熟,技术难度可控,实施周期明确。





