
EN
在金融文档智能识别领域,大模型的泛化能力为金融业务自动化带来了无限遐想,用大模型进行OCR识别,可以轻松抽取任意文档版式。
然而,这也带来了新的问题,大模型如果不经过二次开发,满足不了数据溯源需求。当模型从识别出一个关键财务数据,却常常无法提供该结果在原文中“所见即所得”的绝对证据。
对于任何需要存档、审计、追责的严肃文档处理工作,这种“看似正确”但无法溯源的识别结果,是合规体系中一个无法容忍的断点,基本不能满足生成需求。
想象以下场景:
●信贷审批: 根据一份复杂的财报,建议拒绝一笔贷款。当审批人员追问“具体是财报中哪一项数据导致此结论”时,通用大模型只能给出一个基于概率的模糊解释,而无法指向原文的具体条款。
●保险理赔: AI自动从医疗记录中提取了理赔金额。在后续的赔付争议中,如果无法提供该金额在几十页医疗报告中原始出处的铁证,保险公司将陷入巨大的法律和财务风险。
●合规审计: 监管机构前来审查,要求提供某项交易决策所依据的合同条款。如果AI系统无法提供从决策结果到合同原文的清晰映射,企业将可能面临巨额罚款。
对于金融行业而言,其可解释性和可复核性更为关键。一个无法被审计的AI,无论多“智能”,都是一个不可用的系统。
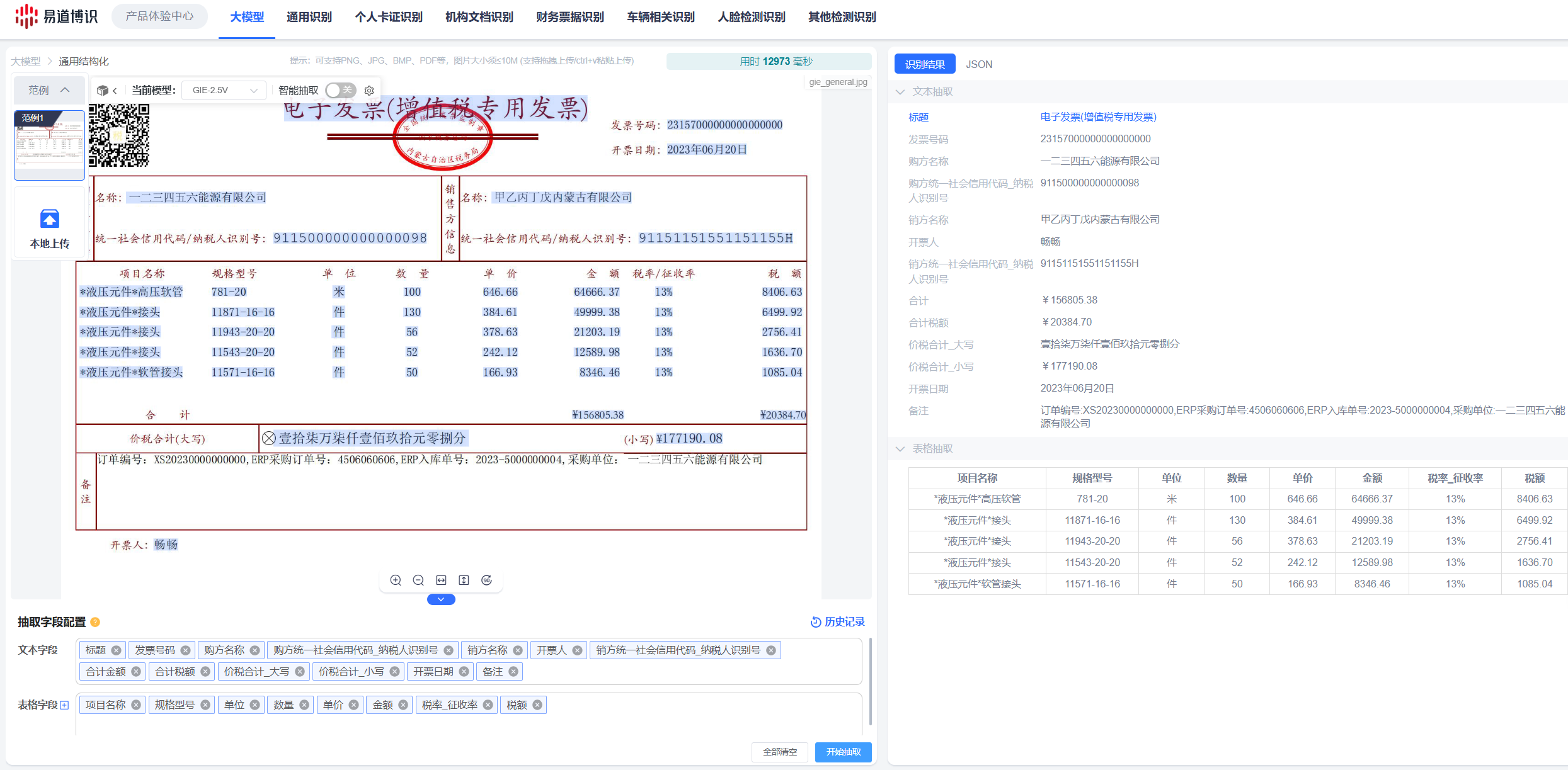
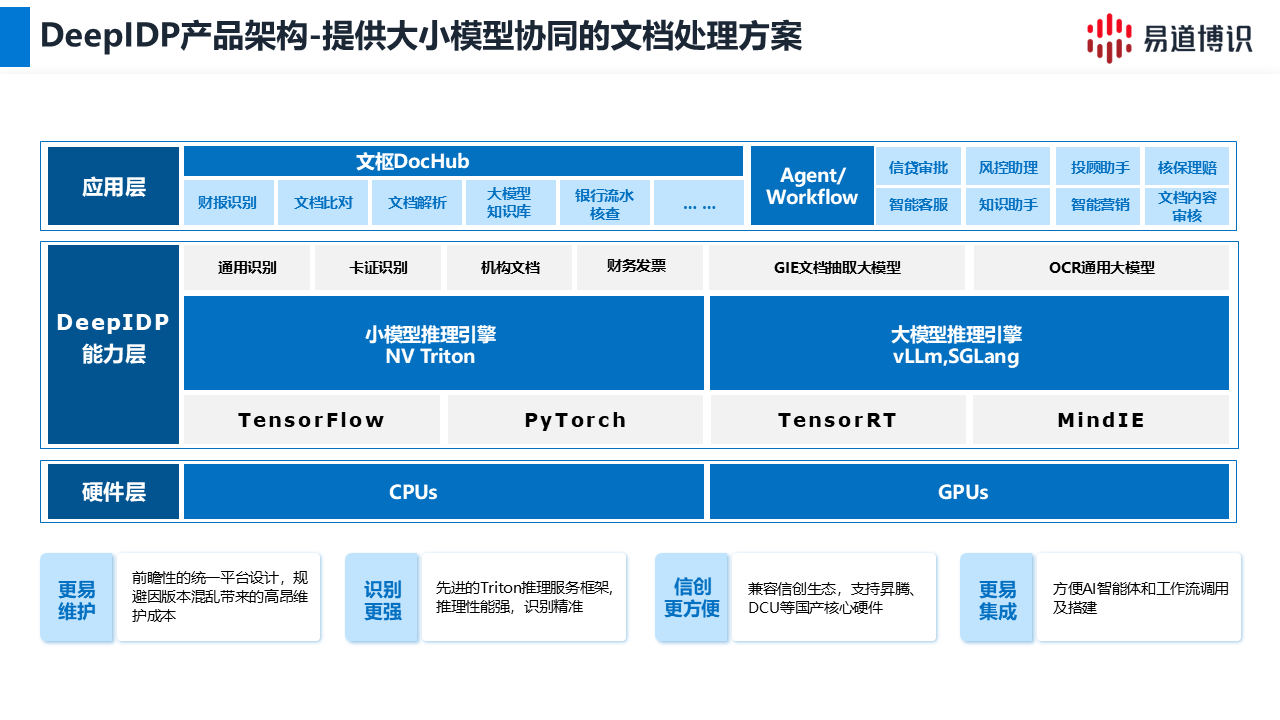
易道博识智能文档处理平台(简称DeepIDP),通过大小模型协同的架构,提供全面的文档处理能力,值得一提的是,智能文档处理平台支持字段级数据溯源。
这个功能在实践中意味着:
当业务人员、风控官或审计员查看系统从一份长达50页的招股说明书中抽取的“承诺发行总额”字段时,DeepIDP即可立刻在原始文档的PDF影像上,高亮框选出该数字所在的具体段落、表格和位置。
这种所见即所得的溯源能力,带来了三大核心价值:
1.结果可复核: 将AI的“黑箱”操作,变为一个完全透明、可供人工快速验证的“白箱”流程。
2.过程可追溯: 建立起从结构化数据到非结构化原文的完整证据链,让每一次AI处理都有据可查。
3.全面可审计: 完美满足监管部门对系统决策可解释性的要求,让企业放心大胆地将AI用于核心业务。
问题1:小模型会被大模型彻底取代吗?
回答: 不会。在可预见的未来,两者将长期共存。小模型在特定任务上的效率、成本和稳定性优势是通用大模型难以企及的。未来的趋势是大小模型的深度协同,而非替代。
问题2:如何判断一个文档处理任务应该用大模型还是小模型?
高频标准文档用OCR小模型:每日需要处理数万张的增值税发票、身份证、银行流水或标准化的入库单。
长尾低频文档用大模型:需要审核的商业合同、法律文书、非标业务申请表、市场研究报告等。这些文档可能每天只处理几十份,但每一份的版式和语言风格都可能不同。
DeepIDP在底层集成了小模型推理引擎和大型模型推理引擎。该架构可以根据任务的复杂度和需求,自动调度最合适的模型进行处理,对外提供标准化的服务接口。
这种融合架构屏蔽了底层模型的差异,实现了“无感调用”,用户无需刻意区分某个识别能力是由大模型还是小模型提供,只需专注于自身业务需求即可。





