
EN
随着人工智能技术在金融、审计、财务共享等领域加速应用,越来越多企业开始通过财务报表OCR,将PDF、Excel、扫描件和手机照片中的财务数据自动提取出来。
但在真实业务中,财报处理的难点早已不只是“能不能识别文字”。
一份财务报表即使所有文字和数字都被正确识别,如果金额对应错了科目、本期数与上期数发生错位,或者“万元”被当成“元”处理,最终得到的数据依然无法直接进入信贷、审计、风控和财务分析系统。
因此,企业选择财务报表OCR时,不能只关注字符识别率,还需要考察系统能否完成表格结构还原、财务字段理解、科目映射、数据归一化、规则校验和人工复核。
财报OCR的最终目标,是把不同来源、不同格式和不同模板的财务报表,转换为统一、准确、可追溯、可进入业务系统的标准化数据。
普通OCR主要解决图片或文档中的文字识别问题,例如识别一段文字、一个数字或一个表格单元格。但财务报表OCR面对的是更复杂的业务结构。
以资产负债表为例,系统不仅要识别“货币资金”和对应金额,还需要判断该金额属于期初还是期末,单位是元还是万元,报表属于合并口径还是母公司口径,以及该科目在企业内部系统中应该对应哪个标准字段。
因此,完整的财报处理通常包含多个环节:
文档预处理、报表分类、表格结构解析、科目与金额提取、期间和单位识别、科目映射、数据归一化、业务规则校验、人工复核以及标准化输出。
其中任何一个环节出现问题,都可能影响最终数据的可用性。
例如,OCR准确识别出了数字“12,500”,但如果系统将其放入错误的表格列,或者忽略报表中的“单位:万元”,那么数据即使在字符层面没有错误,进入后续系统后仍然会造成严重偏差。
这也是为什么企业不能仅用“文字识别率”评价财报OCR。
在产品演示中,财报通常页面清晰、格式标准、表格完整。但企业实际接收到的财报,来源和质量往往非常复杂。
有些财报来自电子版PDF,有些是扫描件、Excel、Word文档或手机拍摄图片;同一批材料中,还可能同时包含财务报表、审计报告、报表附注和其他证明文件。
图片本身也可能存在旋转、倾斜、透视变形、反光、阴影、折痕、印章遮挡、手写批注和分辨率不足等问题。
在表格结构方面,财报还经常存在多级表头、无框线表格、合并单元格、科目缩进、跨页表格、表头跨页丢失,以及一页中包含多个不同表格等情况。
更重要的是,财务报表并不存在完全统一的模板。

不同企业、行业和会计口径下,即使都是资产负债表,科目名称、排列顺序、字段层级和表格样式也可能存在差异。如果系统只能依赖固定模板,一旦遇到新格式,就可能需要重新配置,难以满足大规模、持续性的业务处理需求。
易道博识财务报表智能录入系统面向真实业务材料,支持对不同来源和格式的财报进行统一接入。对于旋转、倾斜、扭曲和透视变形等情况,系统可先进行图像预处理,再开展文档识别和表格解析,为后续数据提取提供相对稳定的基础。
很多财报OCR产品能够完成表格识别和数据提取,但识别结果仍然不能直接进入企业内部系统,其中一个重要原因,就是缺少数据归一化能力。
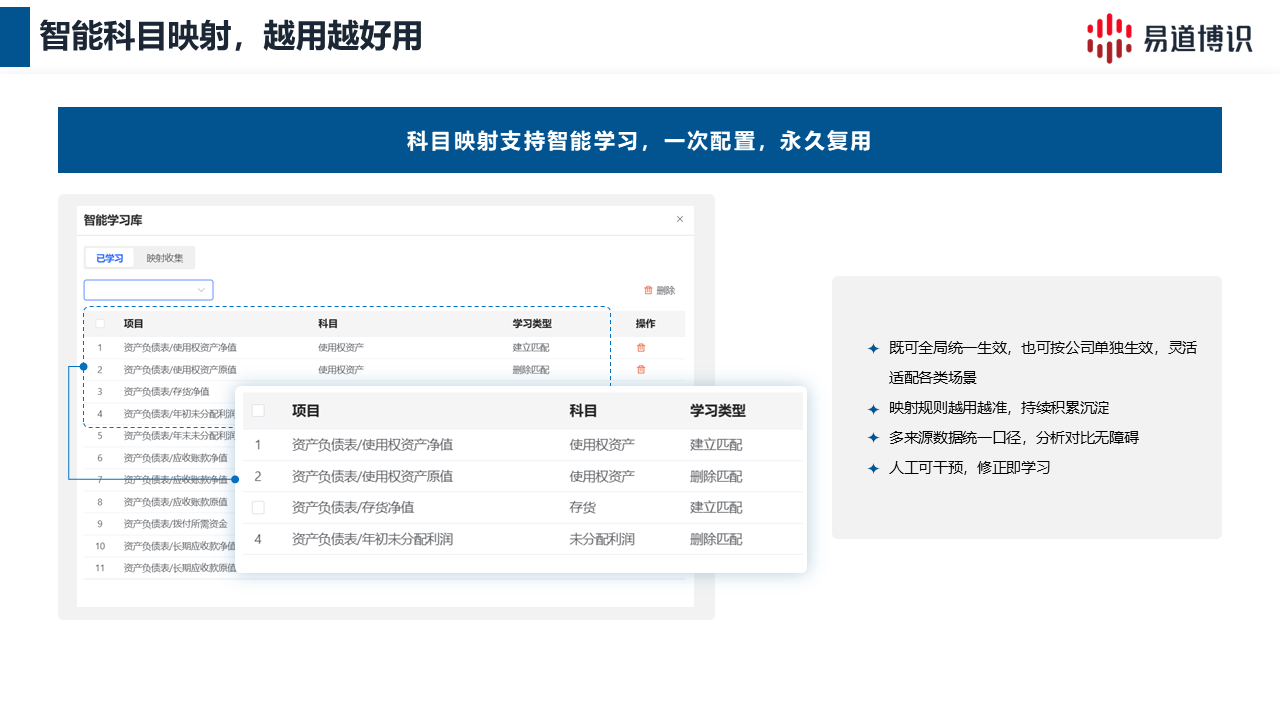
不同企业可能使用不同名称表达相近的财务科目。
例如,与现金相关的项目,可能被写成“货币资金”“现金及现金等价物”“现金和银行存款”等。对于人工阅读而言,这些名称比较容易理解;但对于信贷系统、风控模型或财务分析平台而言,数据必须进入统一的标准字段。
因此,财报处理不能停留在原始字段提取,还需要建立原始科目与标准科目之间的映射关系。
经过归一化后,不同企业、不同年度和不同模板下的财报数据,才能在统一口径下进行比较、分析和调用。
这也是易道博识财务报表智能录入系统与单纯文字识别工具之间的重要区别:系统不仅关注财报上写了什么,还要解决数据应该如何进入后续业务流程的问题。
企业处理财报时,通常不仅需要识别资产负债表、利润表和现金流量表三大主表,还可能涉及所有者权益变动表、财务报表附注、审计报告和报表封面信息。
除科目和金额外,系统还需要识别企业名称、报表日期、会计期间、金额单位、币种、合并口径、母公司口径、本期数、上期数、期初数和期末数等上下文信息。
在同一个财报文件中,还可能同时出现多个年度、多种报表口径以及多个主体的数据。如果系统无法正确区分,就可能造成不同年度或不同口径的数据混用。
对于银行授信、投资尽调和审计等场景,财报附注同样具有重要价值。很多主表中的金额,需要结合附注明细才能进一步理解其构成和变化原因。
因此,企业在进行财报OCR选型时,需要确认产品究竟只能识别标准三张表,还是能够处理完整财报文件中的多种文档和复杂表格。
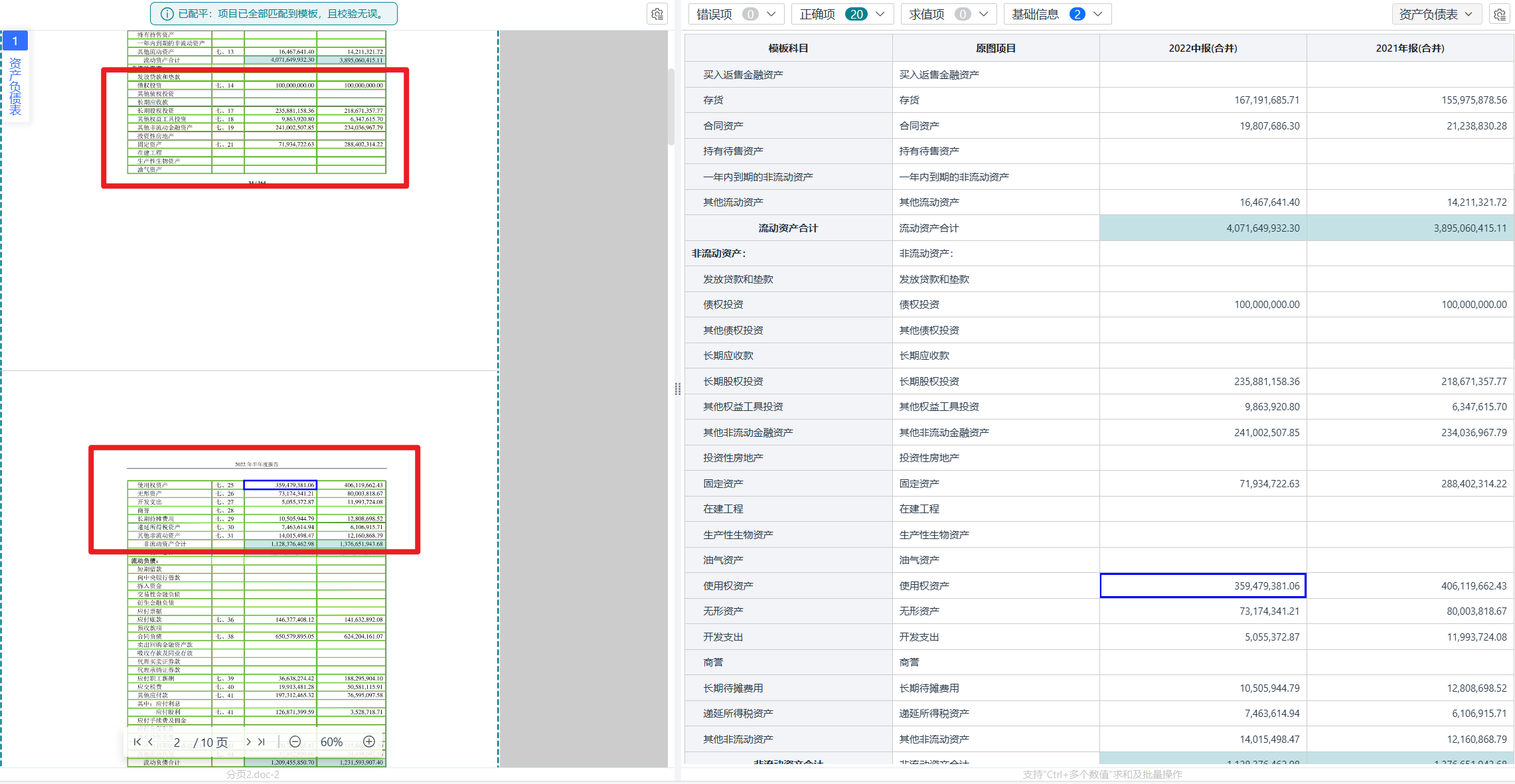
财务数据具有较高的准确性要求,完全依靠OCR结果自动入库,往往存在一定风险。更合理的处理方式,是将模型识别、业务规则和人工复核结合起来。
系统可以根据项目实际业务规则,对表内计算关系、表间数据关系、科目缺失、重复字段、金额单位异常、期间不一致等问题进行检查。
例如,资产总计与负债和所有者权益总计是否一致,各明细项之和是否与合计项一致,主表数据与附注明细是否存在明显差异。
当系统发现低置信度字段或规则异常时,可以将相关内容标记出来,进入人工复核环节,而不是让所有数据都依赖人工逐项检查。
在复核过程中,原始财报与识别结果应当能够对应展示。工作人员可以快速定位字段所在页面和位置,检查科目、金额、期间及单位是否正确,并对异常数据进行修改。
同时,修改过程应尽可能保留操作记录,使后续数据能够追溯到来源文件、原始页面和复核过程。
财报OCR的价值,最终需要通过业务系统体现。
经过识别、归一化、校验和复核的数据,可以根据企业需求输出为结构化文件或通过接口传递至信贷系统、审计系统、风险管理平台、财务共享平台、企业评级系统和其他内部应用。
不同企业内部系统的字段定义、科目编码和数据格式通常并不一致。因此,财报OCR项目还需要考虑字段映射、接口适配、异常状态传递和复核状态管理。
企业在选型时,不仅要询问“能不能识别”,还需要确认:
识别结果能否按照内部字段标准输出;数据出现异常后如何处理;每一项数据能否定位到原始文件;系统能否适配现有业务流程和部署环境。
只有完成这些环节,财报OCR才能从一个识别工具,转变为真正可落地的财务数据基础设施。
可以,但不同文件类型的处理方式不同。电子PDF和Excel通常包含较完整的文本或表格结构,扫描PDF和手机照片则需要先进行图像校正和文字识别。选型时应重点测试系统对旋转、倾斜、透视变形、低分辨率和印章遮挡等真实材料的处理能力,而不能只测试标准电子文件。
因为文字识别正确,不代表数据关系正确。数字还可能出现科目对应错误、行列错位、期间混淆、单位遗漏或报表口径错误。财报数据要直接进入业务系统,还需要完成表格结构还原、科目映射、数据归一化、规则校验和人工复核。
建议使用企业自身的真实财报开展POC,样本应覆盖不同格式、模板和复杂情况。测试时不仅要看字符识别率,还要考察结构还原、科目与金额对应、期间和单位识别、数据归一化、异常发现、人工复核以及系统对接能力。最终判断标准应是数据能否稳定进入真实业务流程。





