
EN
传统手工录入一份财报平均耗时达几小时。而结合了深度学习OCR与自然语言处理技术的智能财报识别系统,能将这一过程压缩至5分钟,并且识别准确率超过99.5%。
金融机构的财务部门往往是数据处理压力最大、容错率最低的环节。无论是银行的信贷审批要求快速响应,融资租赁公司的尽职调查需要穿透到底,这些复杂的业务场景都指向同一个基础动作——处理海量、跨期的财务报表。
然而,很多企业面对格式各异、科目繁杂的财报,如果依然依赖人工“肉眼看、手工敲”的原始方式,不仅单份耗时常常达 2到 3小时,业务高峰期更是容易形成瓶颈。
很多人对“财报识别”的认知还停留在初级阶段,误以为它只是简单地把图片上的文字框选并提取出来。其实,单纯的通用文字提取能力(OCR)一旦放入复杂的财报场景中,就会面临巨大的挑战:
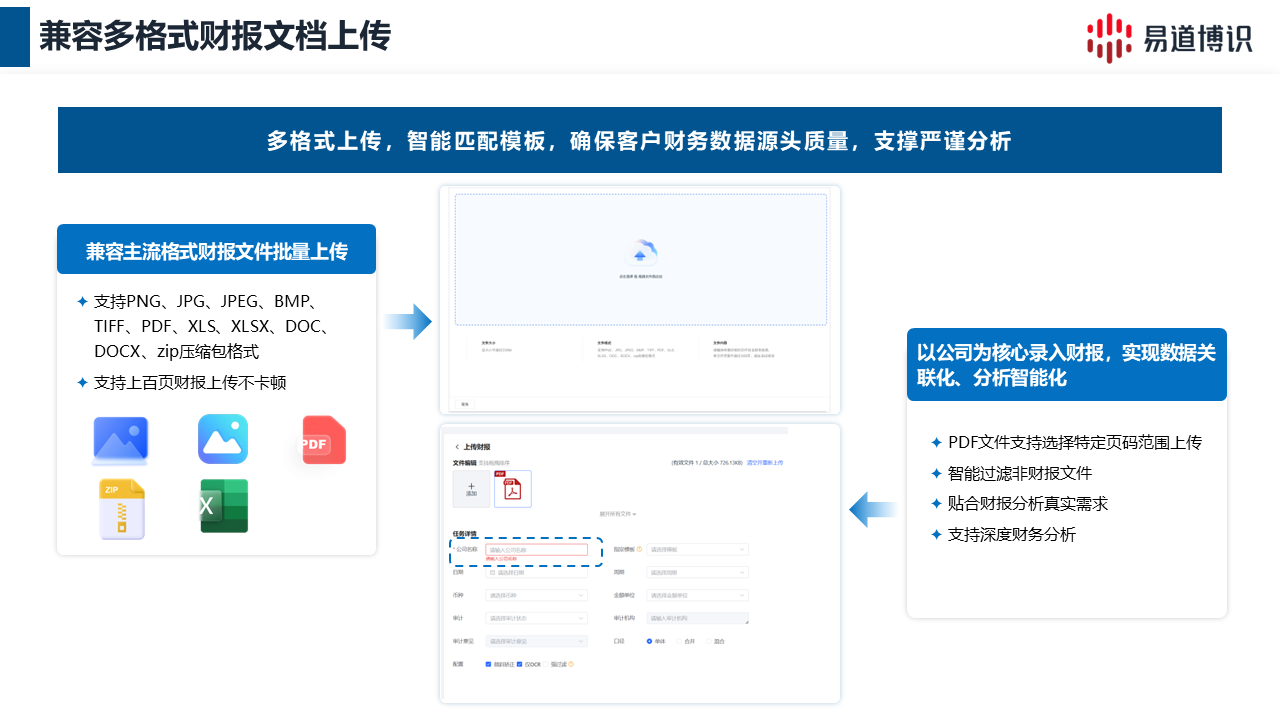
●格式多样难处理:一般企业、金融企业、医疗卫生机构或事业单位的财报版式完全不同,通用的 OCR 难以判断表格层级。
●科目映射紊乱:不同企业的财报叫法各异,有的把“货币资金”写成“现金”,有的记作“现金及现金等价物”,简单的文字提取无法解决归一化问题。
●表格结构异常复杂:财报中经常出现跨页表格、无边框表格,或者因为打印扫描环境不佳导致的倾斜、模糊干扰。
以易道博识智能财报录入系统为例,当一线人员将一份财报(无论它是 PNG、JPG 测试图片,还是 PDF 文档、多页 Excel 表格,甚至是包含各种乱码文件的 ZIP 压缩包)上传后,系统首先会智能过滤掉非财报文件。接着会自动判断当前的报表类型属性。通过系统内置的标准化财报模板库(该库已覆盖一般企业、金融、医疗卫生等跨行业的标准化范式),将原图原表上的科目提取出来,数据归一化处理。
面对市场上琳琅满目的识别工具,企业管理者在选型时应该重点考量哪些维度的能力?
1.具备自动配平能力
优秀的业务系统(如易道博识)会在前端识别之上,深度内置强悍的勾稽关系校验规则。例如,基于最核心的“资产=负债+所有者权益”,系统会在识别提取后,立刻对所有涉及的数据进行实时嵌套校验与全自动配平。
在业务人员面对的可视化操作界面上,所有的正确项、错误项和潜在问题项都会被智能颜色区分。若未配平,系统可引导客户经理智能配平。
2. 多维度的经营分析
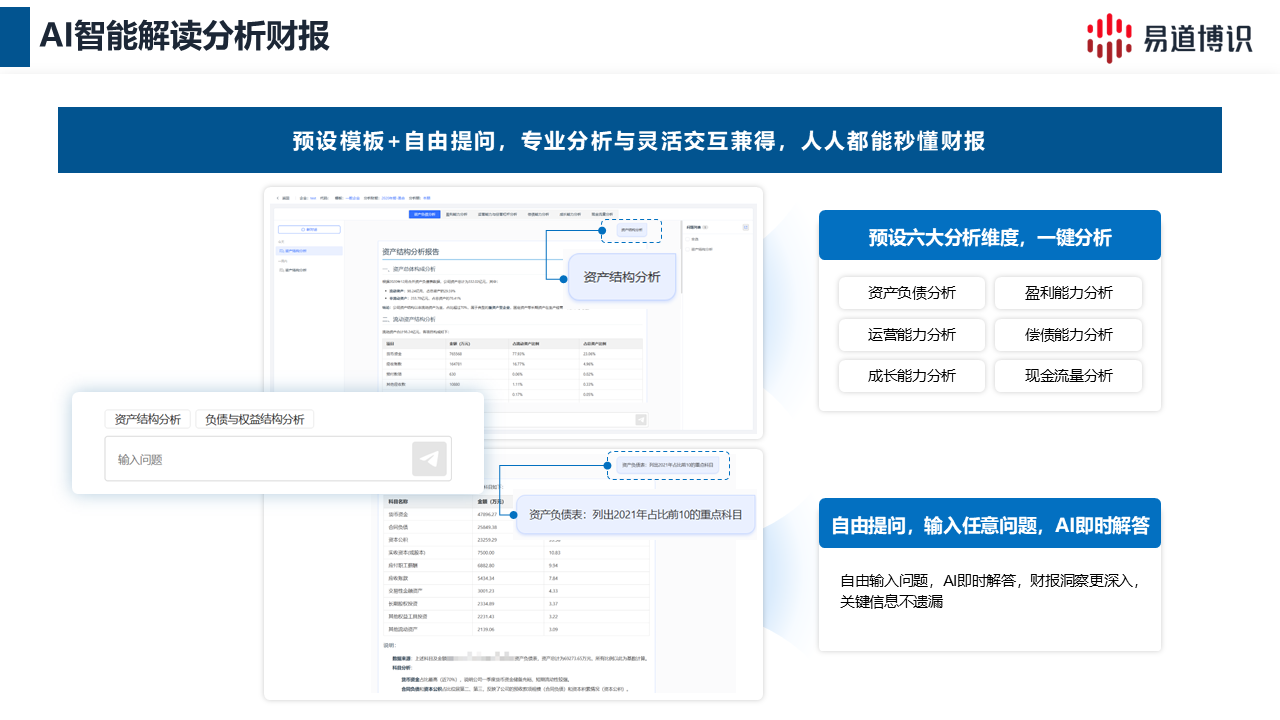
数据的识别与录入只是整个风控周期的第一步,数据的最终使命是被整合与分析利用。
智能财报录入系统允许企业将“客户个体”作为管理单元,按客户主体、按不同期次建立结构化任务。这就从根源上避免了多期次数据的口径混乱、重复提交和严重的数据冗余。
AI分析,自动生成覆盖盈利能力、偿债能力、营运能力、发展能力这四大维度的全景财务分析报告。
问题:财报格式和科目名称都不一样,怎么统一识别并对齐?
回答:易道博识系统内置跨行业模板,无论原格式多复杂,上传瞬间即可通过自适应技术自动建立规范的财务科目映射。
问题:智能财报OCR系统如何保证识别后的业务数据不出错?
回答:除99.5%的高优识别精度,易道博识系统通过强大的内置会计勾稽公式,自动配平校验
问题:财报录入系统录入效果如何?
回答:将单份处理耗时从3小时压缩至5分钟,还可一键导出涵盖四大维度的全景财务分析报告,大幅提效防范风险。





