
EN
文档,作为知识和信息的关键载体,智能化处理需求日益迫切。
在这一进程中,大型语言模型(LLM)以其强大的自然语言理解能力崭露头角,有人指出:大模型也能进行文字抽取,那么各类OCR小模型会被代替吗?
大预言模型凭借在海量文本数据上的训练,在理解上下文、语义理解、文本生成及知识问答等方面潜力巨大。LLM能够深入分析非结构化文本内容,进行智能摘要、主题提炼、情感分析,甚至可以基于文档内容进行多轮对话式的信息检索和复杂问题的解答。
尽管在文本理解层面表现出色,但任何智能分析的前提是获得准确、可靠的原始数据。在文档智能流程中,将图像形态的文档(如扫描件、照片)转化为机器可读文本的光学字符识别(OCR),扮演着信息输入的关键角色。
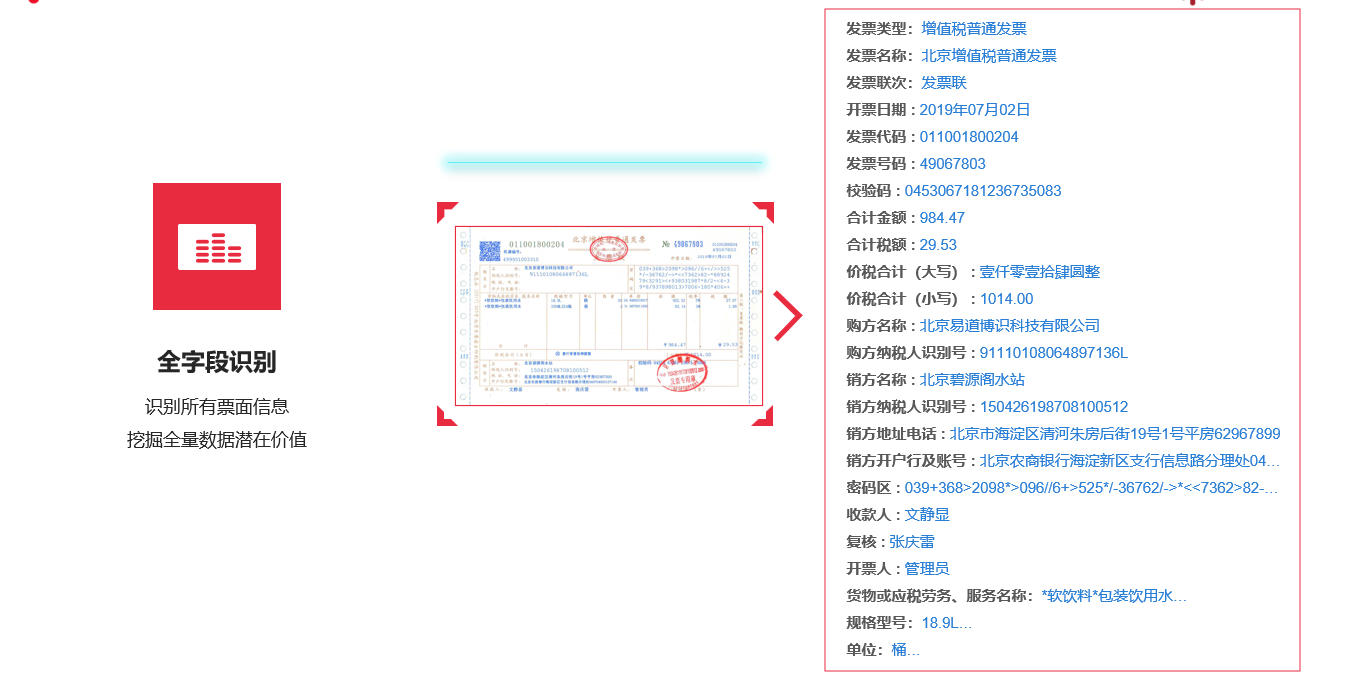
专业OCR小模型针对特定识别任务(如身份证、银行卡、各类票据、特定行业报告等)进行了深度优化。通过在特定数据集上的针对性训练、对特定版式和字符的适应性调整,以及对噪声、低分辨率等图像问题的处理算法,专业OCR能够在复杂场景下实现高精度的文字提取。其优势在于:
1.高准确率: 对于版式相对固定或有明确提取需求的文档,专用OCR能达到非常高的字符识别准确率和字段提取准确率。
2.可靠性: 专用OCR系统在设计上更注重对原始图像信息的忠实转换,产生“幻觉”或无中生有信息的风险远低于生成式的大型模型,这对于后续决策的正确性至关重要。
3.效率与成本: 在处理大规模、标准化的识别任务时,优化后的专用OCR通常具有更快的处理速度和更低的单位处理成本。
因此,专业OCR小模型是确保后续智能化处理获得高质量数据的基础保障。
大型语言模型与专业OCR小模型并非相互替代的关系,而是高度互补。
一个典型的协同工作流如下:
前端精准数据捕获: 专业OCR系统首先对各类文档图像进行处理,精准识别文字信息,并可根据预设规则提取关键字段,形成结构化或半结构化的文本数据。这一步确保了进入后续环节的数据质量。
后端智能分析与应用: 经过OCR处理的高质量文本数据,随后被送入大型语言模型。LLM利用其强大的语义理解能力,对这些数据进行深层分析、逻辑推理、信息关联、智能校验或生成报告。例如,LLM可以校验OCR提取的合同条款是否符合公司规范,或基于提取的发票信息自动生成会计分录建议。
这种协同模式,既发挥了专业OCR在数据提取准确性上的优势,又利用了大型语言模型在理解和处理复杂信息上的长处。
易道博识提供了涵盖7大类、超过60种的标准化OCR产品,这些服务支持自由选配、快速部署,能够实现开箱即用,满足了用户对不同类型文档的快速、标准化识别需求。
更进一步,针对通用文档抽取的需求,易道博识推出了其GIE(General Information Extraction)大模型。这是一款基于海量金融文档数据训练的OCR大模型,其核心目标是实现对任意版式文档(包括结构化和非结构化文档,以及复杂表格)的通用信息抽取能力。它通过深度融合版式特征与语义特征,无需预设模板即可实现高精度的关键信息提取。

大型语言模型和专业OCR技术各有其核心优势和最佳适用场景。将两者视为孤立的技术路径,或者简单地认为一方将完全取代另一方,都是片面的。未来的趋势必然是两者的深度融合与协同工作,通过优势互补,共同提升文档信息的提取、理解和应用水平。






